data morph¶
Local CSV / JSON / TXT file conversion with a distilled Gemma model.

![]()
![]()
data morph distills a file-format-conversion capability from Claude Opus into a 2.0 GB Gemma student that runs locally — so you can convert between CSV, JSON, and TXT for free instead of paying for frontier-LLM API calls. AI Builders 2026.
from datamorph import convert_file
result = convert_file("contacts.csv", "contacts.json")
print(result.accepted, result.scores)
How it works, in one picture¶
The model never sees the full source file — only a small metadata envelope. From that, it writes a Python script that does the conversion, which is then run in a sandbox and validated.
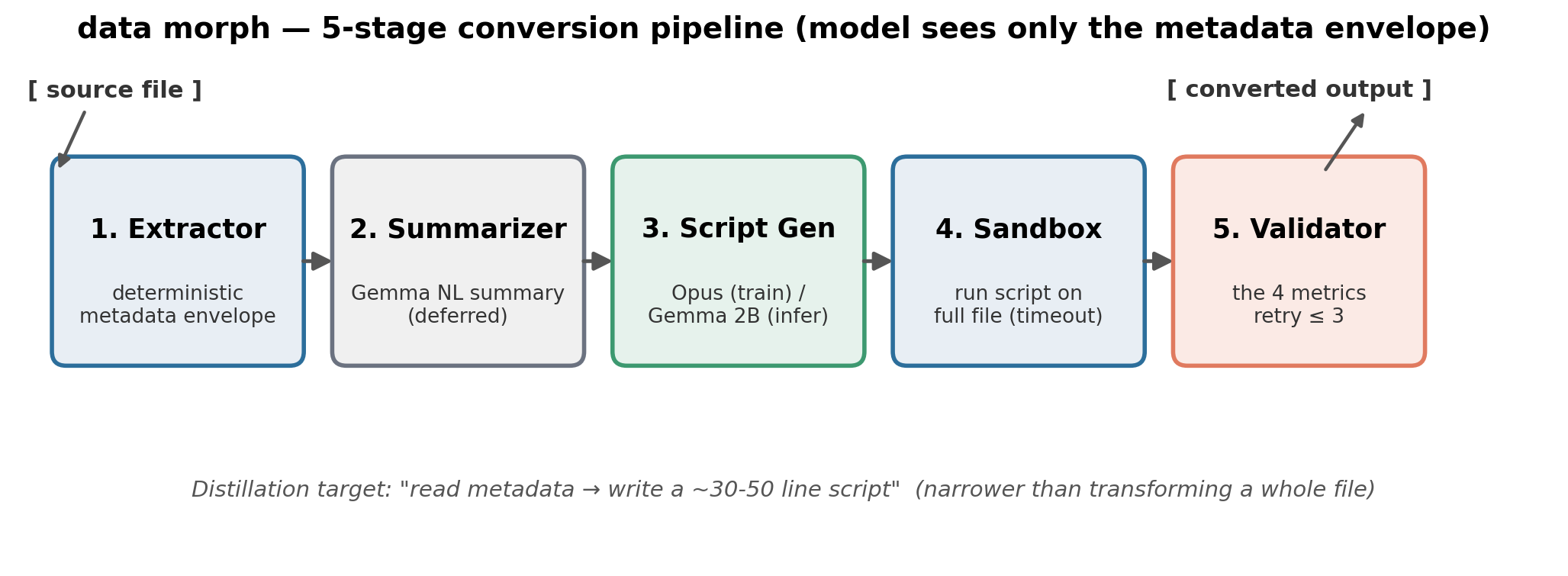
See How it works for the full five-stage pipeline.
Why a small local model?¶
Rule-based parsers can't handle messy, context-dependent conversions. Frontier LLMs can, but they're expensive at scale. data morph narrows the task from "transform a whole file" to "read metadata, write a script" — realistic for a 2 B model, and it scales to arbitrary file sizes because the model never reads full file content.
Results¶
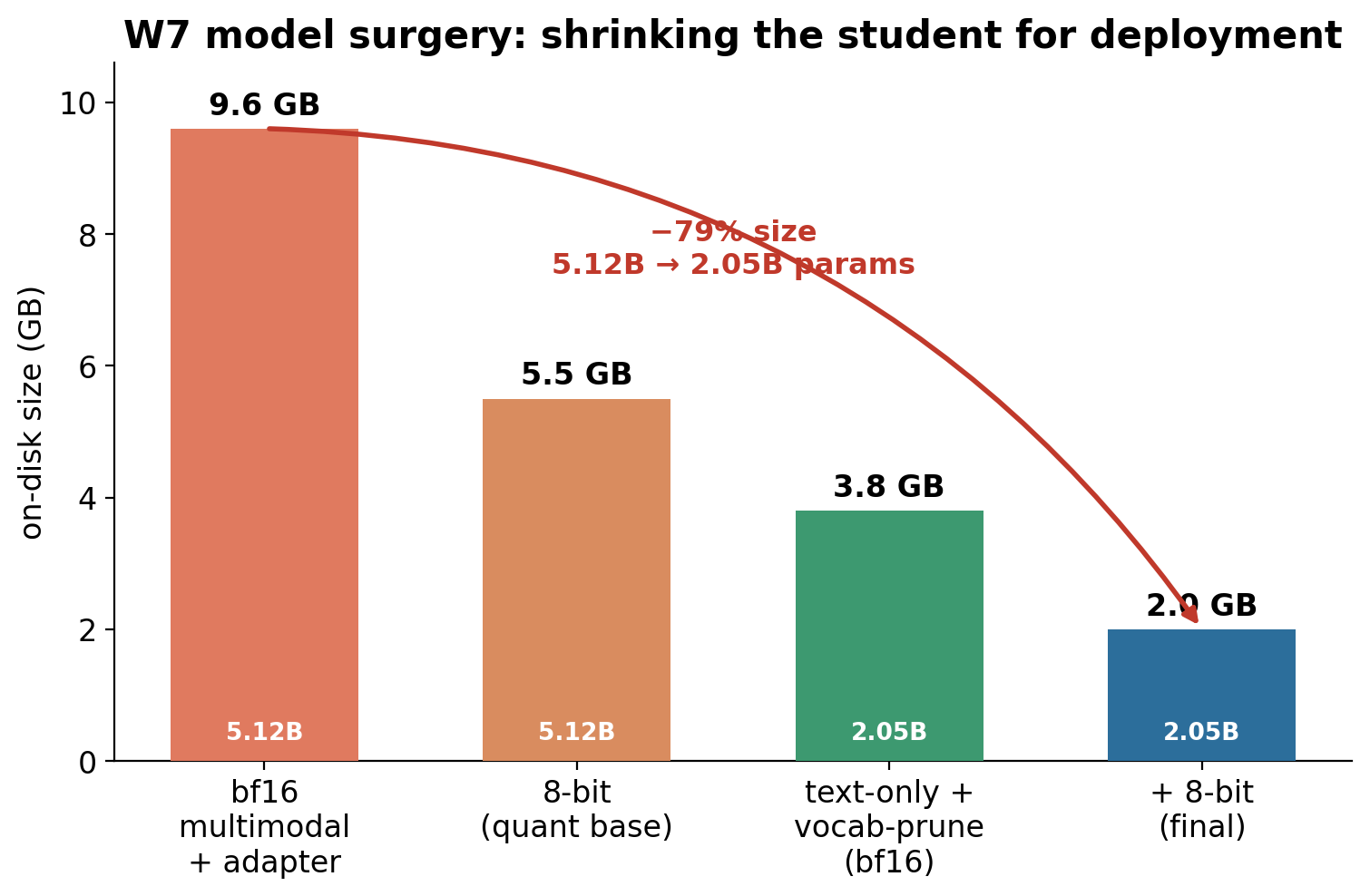
A three-step model surgery (fuse LoRA adapter → strip vision/audio towers → prune the vocabulary 262 k → 16 k → 8-bit quantize) shrinks the student 9.6 GB → 2.0 GB (−79 %) while staying at ~96 % of teacher accuracy.
| Artifact | params | size | retry≤3 | % of teacher |
|---|---|---|---|---|
| fused + text-only + vocab-16k, bf16 | 2.05 B | 3.8 GB | 69/70 (0.986) | ~99 % |
| + 8-bit (shipped) | 2.05 B | 2.0 GB | 67/70 (0.957) | ~96 % |
Next steps¶
- Quickstart — install and run your first conversion.
- Showcase — real, messy files converted end to end.
- API reference —
convert_file,ConversionResult,resolve_model.